
6 skills required to be a senior software engineer
I’ve seen so many senior engineers struggle with these skills during technical interviews related to system design, whiteboarding and practical coding. Master these to standout!

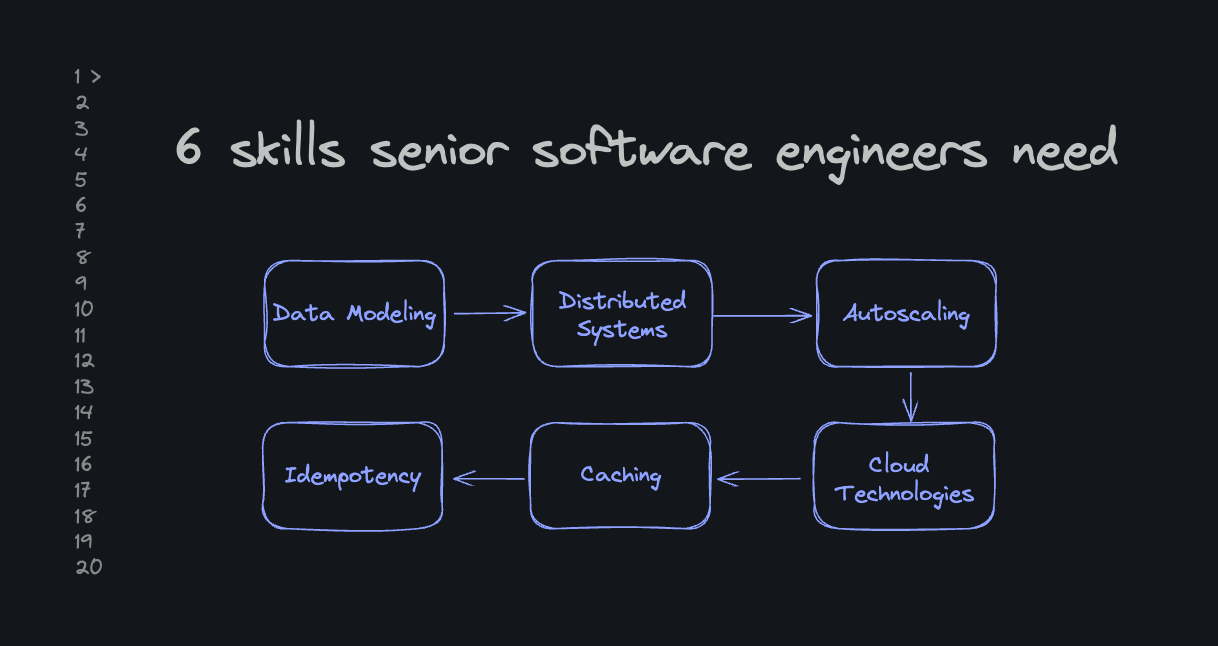
In order to level up massively and work towards senior software engineering positions, You need to grow beyond “I can build a basic app.”
What we usually mean by that is, I can:
Write some CRUD APIs
Spin up a database + server
Awesome as a junior/mid-level. Won’t cut it for a senior engineer and beyond.
I’ve seen so many awesome engineers struggle during practical data modeling, coding, or whiteboarding rounds because they don’t have good experience and understanding in these 6 key areas.
You’ll need to develop expertise and experience in them if you want to grow into senior+ software engineering positions.
1. Data Modeling
Learning how to model data well is an underrated skill in our industry.
Senior engineers are usually tasked with leading larger new projects that might not be a solved problem, or require new data models and solutions. You’ll be tasked to come up with a data model / architecture that:
solves your unique problem
fits with your existing systems
can be easily extended
is performant
A lot of data modeling is going to be in databases – whether relational, or document-based, so you’ll want to get good at both of these – not just Mongo.
The core of data modeling comes down to Entities, Attributes, and Relationships.
Here’s a really helpful summary from this article by Seckin Dinc, Head of Data and Product at FreeNow:
Entity
An entity is a real-world object or concept that can be uniquely identified and described, such as a person, place, thing, event, or concept. An entity is typically represented by a table in a relational database, and each instance of the entity is represented by a row in the table.
Attribute
An attribute is a characteristic or property of an entity, such as a name, age, address, or color. Attributes are represented by columns in the table that represents the entity.
Relationship
A relationship is a connection or association between two or more entities. Relationships describe how entities interact or relate to each other, and are represented by lines or connectors between the entities in a data model.
Relationships can be one-to-one, one-to-many, or many-to-many.
This just scratches the surface of data modeling, at some point you’ll want to deep dive into a book on data modeling like:
2. Events, Message Queues, and Workers
A lot of companies today are building / working in distributed systems that process work in real-time (APIs), but also asynchronously (queues + workers).
An asynchronous or event driven system is really a different mental model to become familiar and confident in, so it’s worth spending time learning it.
One of the key pieces of an asynchronous system is message queues. Message queues are really useful when working with micro services. You can use them to:
Rate limit processing of events
Communicate between micro services
Shard the load of specific types of events to be processed at different rates
Batch process a bunch of events
Here’s an example:
Let’s say your app needs to send out an email campaign to millions of customers. Rather than spinning up one mega server to handle and send out all the emails.
throw those emails on a queue
have worker pods scale and pick them up
send out the emails asynchronously
Message queues can also be used for interservice communication.
If an action / event:
Doesn’t need instant feedback
Spans several domains
Is used by multiple consumers
It’s a great candidate for events + message queues.
eg. customer orders, uses coupon, needs receipt email
3. Autoscaling infrastructure
Autoscaling… ahh… the fancy buzzword that we all like to throw around.
But really, it’s super important when you are working on systems that have spiky load, or need to scale without human resources.
Keep reading with a 7-day free trial
Subscribe to Level Up Software Engineering 🚀 to keep reading this post and get 7 days of free access to the full post archives.